Indexación espacial¶
Note
| Fecha | Autores |
|---|---|
| 1 Noviembre 2012 |
|
| 15 Octubre 2013 |
|
©2012 Micho García
Excepto donde quede reflejado de otra manera, la presente documentación se halla bajo licencia : Creative Commons (Creative Commons - Attribution - Share Alike: http://creativecommons.org/licenses/by-sa/3.0/deed.es)
La indexación espacial es una de las funcionalidades importantes de las bases de datos espaciales. Los indices consiguen que las búsquedas espaciales en un gran número de datos sean eficientes. Sin idenxación, la búsqueda se realizaria de manera secuencial teniendo que buscar en todos los registros de la base de datos. La indexación organiza los datos en una estructura de arbol que es recorrida rapidamente en la búsqueda de un registro.
Como funcionan los índices espaciales¶
Las base de datos estándar crean un arbol jerarquico basados en los valores de las columnas. Los indice espaciales funcionan de una manera diferente, los índices no son capaces de indexar las geometrías, e indexarán las cajas (box) de las geometrías.
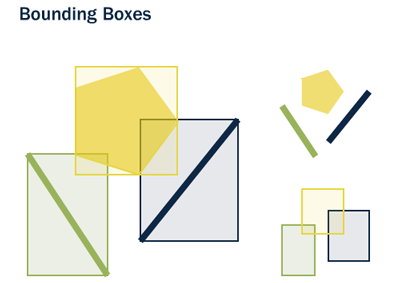
La caja (box) es el rectángulo definido por las máximas y mínimas coordenadas x e y de una geometría.
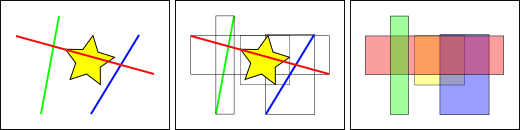
En la figura se puede observar que solo la linea intersecta a la estrella amarilla, mientras que si utilizamos los índices comprobaremos que la caja amarilla es intersectada por dos figuras la caja roja y la azul. El camino eficiente para responder correctamente a la pregunta ¿qué elemento intersecta la estrella amarilla? es primero responder a la pregunta ¿qué cajas intersectan la caja amarilla? usando el índice (consulta rápida) y luego calcular exactamente ¿quien intersecta a la estrella amarilla? sobre el resultado de la consulta de las cajas.
Creación de indices espaciales¶
La síntaxis será la siguiente:
CREATE INDEX [Nombre_del_indice] ON [Nombre_de_tabla] USING GIST ([campo_de_geometria]);
Esta operación puede requerir bastante tiempo en tablas de gran tamaño.
Uso de índices espaciales¶
La mayor parte de las funciones en PostGIS (ST_Contains, ST_Intersects, ST_DWithin, etc) incluyen un filtrado por indice automáticamente.
Para hacer que una función utilice el índice, hay que hacer uso del operador &&. Para las geometrías, el operador && significa “la caja que toca (touch) o superpone (overlap)” de la misma manera que para un número el operador = significa “valores iguales”
ANALYZE y VACUUM¶
El planificador de PostGIS se encarga de mantener estadísticas sobre la distribución de los datos de cada columna de la tabla indexada. Por defecto PostgreSQL ejecuta la estadísticas regularmente. Si hay algún cambio grande en la estructura de las tablas, es recomendable ejecutar un ANALYZE manualmente para actualizar estas estadísticas. Este comando obliga a PostgreSQL a recorrer los datos de las tablas con columnas indexadas y actualizar sus estadísticas internas.
No solo con crear el índice y actualizar las estadísticas obtendremos una manera eficiente de manejar nuestras tablas. La operación VACUUM debe ser realizada siempre que un indice sea creado o después de un gran número de UPDATEs, INSERTs o DELETEs. El comando VACUUM obliga a PostgreSQL a utilizar el espacio no usado en la tabla que dejan las actualizaciones y los borrados de elementos.
Hacer un VACUUM es crítico para la eficiencia de la base de datos. PostgreSQL dispone de la opción Autovacuum. De esta manera PostgreSQL realizará VACUUMs y ANALYZEs de manera periodica en función de la actividad que haya en la tabla:
VACUUM ANALYZE [Nombre_tabla]
VACUUM ANALYZE [Nombre_tabla] ([Nombre_columna])
Esta orden actualiza las estadísticas y elimina los datos borrados que se encontraban marcados como eliminados.
Prácticas¶
- Compare los resultados de obtener la población del barrio West Village así como el tiempo necesario para ejecutar cada operación. Use el operador de caja en una si y en otra no.